So what’s AI ?
Me too I don't really know, difficult question to answer but so so easy to ask
Let's try and make a guess:
 If you choose G and P you are right, same if you took Y & B. So What exactly is AI, well you can find any situation where one of these definitions will fit the context, so AI is a little bit of them all.
If you choose G and P you are right, same if you took Y & B. So What exactly is AI, well you can find any situation where one of these definitions will fit the context, so AI is a little bit of them all.
When It All Started
 Well, if you remember well the point where it all started for the in the public domain was back in November 2022, with the first releasse of ChatGPT. After that date other companies such as Google, Antropic, ByteDance etc.. started releassing their LLMs to the public, that's what I called the rumbling of LLMs!
Well, if you remember well the point where it all started for the in the public domain was back in November 2022, with the first releasse of ChatGPT. After that date other companies such as Google, Antropic, ByteDance etc.. started releassing their LLMs to the public, that's what I called the rumbling of LLMs!
As of today now they have evolve in an exponential way, thanks to new optimization algorithms, architecture and so on. You will see them in healtcare with Google's PaLM 2, in coding with Anthropic's Claude Code.
They are incredible indeed!, But as great as they can be, the potential for misuse is also increasing exponentially.
That’s where we need to make a responsile use of AI (llm), and the first step is to get to know it better!
A Look into the Beast
So we say llm all day long, but exactly is it?
 As showcased by the image above, llm is an acronym for Large Language Model, simply put: It's a mathematicall function (model) that has been trained on vast amount of data (large) and is able to converse or generate output in natural language (the language part, like in Ghomala, French or English).
As showcased by the image above, llm is an acronym for Large Language Model, simply put: It's a mathematicall function (model) that has been trained on vast amount of data (large) and is able to converse or generate output in natural language (the language part, like in Ghomala, French or English).

Exactly what you get when chatting with ChatGPT or Gemini right? Here is a high level view of what's happening, don't worry we will be digging into the details thoughout this article:
 So we will go through
So we will go through
- The process of tokenization, what are the tokens? why they exist and how are they used?
- The process of embedding, from token, wordsto vectorin a vector space and someinteresting facts
- Why a step of unembedding is essential, how it works
- Lastly but not least we will look at how the probability distribution is created, and what decisions it help us take.
Tokenization
 As the name implies, it's an operation that willinvolve tokens. But what are tokens? You can think of tokens as words or part of words. For example in the image above I illustrated the process of taking in a sentence like "DevFest is a really great...", when it receive that, throught the process of tokenization we might obtain tokens like "Dev", "Fest", ""is" and so on, you get the point.
As the name implies, it's an operation that willinvolve tokens. But what are tokens? You can think of tokens as words or part of words. For example in the image above I illustrated the process of taking in a sentence like "DevFest is a really great...", when it receive that, throught the process of tokenization we might obtain tokens like "Dev", "Fest", ""is" and so on, you get the point.
Answers to questions will be given at the end :), so keep reading!
There are so many models(yes there are ML model that are just doing that) designed todo tokenization in different ways.
Embeddings
So now we have our tokens, which are just chunk of words, but to the machine, it's not that different since they can only understand numbers(0,1) not words let alone chunk of words. So how do we do to make our model, understand the text given to him? Answer: We make use of Vector Embeddings.
 As you can see from the image, embedding is the operation that takes a token and convert it into a vector, and we call it Vector Embedding. Fascinating right? but how can we convert text into numbers you might ask, well let's look at it now!
As you can see from the image, embedding is the operation that takes a token and convert it into a vector, and we call it Vector Embedding. Fascinating right? but how can we convert text into numbers you might ask, well let's look at it now!
Picture the following, you have a dictionnary of words, 5000 let's say, you want to find the vectors for each of the 5000 words, the naive method will be:
- You take an entry, entry 0 for example, the wordis Morning, you put 1 when you find it and 0 otherwise: so your first vector for Morning will be [1,0,0,0,...,0]. The same will apply for the entry 1, [0,1,0,0,...,0] and the pattern is that for each entry, we will get huge vectors(5000 coordinatesin our case) where we will have a single non null value.
The embedding process is not just about getting vectors out of words, no to really make use of the results, we needthe vectors to be aware of the context in which the words were. So multiple other steps will be added such as : Positional encoding, heping us to keep track of the index of each word in the sentence, Attention mechanism, making wordstalks to each other or exchange information to achieve that, a transformer will be used. It's a neural network architecture that speialize in learning context and meaning between sequential data.
That process will be done back-and-forth multipletimes, you will hear of Multi Head Attention Block. The final of result of such operation will be that at the end of it, the last vector now represent the whole meaning of the sentence.
 With that last vector now, the next step is unembedding that same last vector! A simple way to picture it is: We have our final vector representing the whole sentence, we have our vocabulary(words the model already knows about, what it learned during trainning, for LLMs what they learned when being trained on the whole internet) which is a set of vector embedding too, a matrix in fact.
With that last vector now, the next step is unembedding that same last vector! A simple way to picture it is: We have our final vector representing the whole sentence, we have our vocabulary(words the model already knows about, what it learned during trainning, for LLMs what they learned when being trained on the whole internet) which is a set of vector embedding too, a matrix in fact.
 The result of that operation is now a single vector, from there we move on to the probability distribution!
The result of that operation is now a single vector, from there we move on to the probability distribution!
Probability Distribution
Given that the last vector has somehow gained the meaning of the whole sentence, the unembedding process will generate a mapping of words to real numbers, to think of them as real probabilities, we need to normalize it between 0 and 1.

Welcoming Softmax, aka the normalizer!!!
The formula might seem really complicated, but the core idea is that whatever it takes in, it will output something that's in the intervall of 0 and 1.
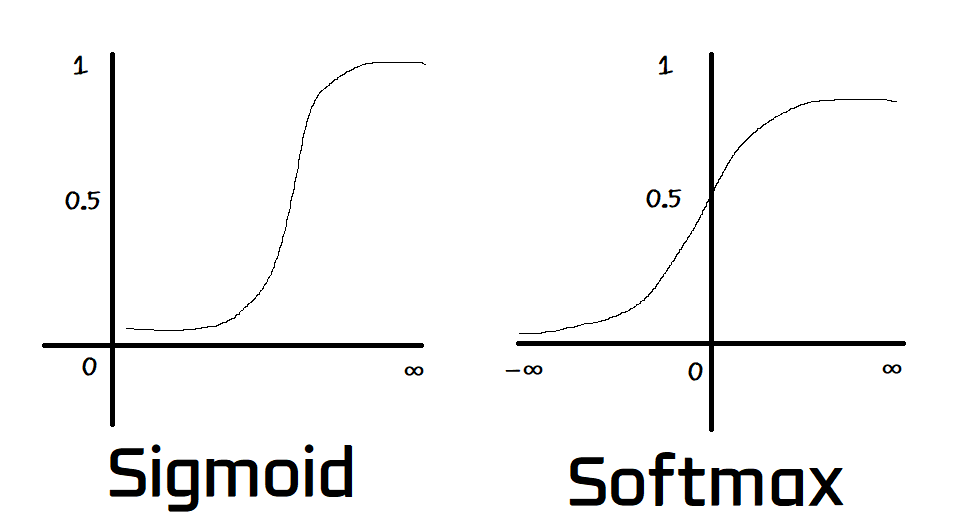 The picture should make it clearer, note that we also have another normalization function called Sigmoid. Doing pretty much the same thing but having a subtle difference.
The picture should make it clearer, note that we also have another normalization function called Sigmoid. Doing pretty much the same thing but having a subtle difference.